GPT-5.5, 이번에도 하루 만에 탑재했습니다. 하룹이 만드는 것은 말 잘하는 AI가 아니라 일을 끝내는 AI입니다.
어제 출시된 GPT-5.5가 오늘 하룹 슈퍼AI에 탑재되었습니다. 지난주 Claude Opus 4.7에 이어 두 번째 익일 탑재입니다. 시장은 여전히 더 잘 말하는 AI를 경쟁하지만, 하룹이 만드는 것은 명령을 이해하는 대화상대가 아니라 병원의 목표를 수행하는 업무자 — 일을 끝내는 AI입니다.

이번 공지의 핵심
- 어제 출시된 GPT-5.5, API 공개 몇 시간 만에 하룹 탑재 완료
- Claude Opus 4.7에 이어 일주일 만에 또 — 신모델 익일 탑재는 하룹의 기본값
- 시장은 더 잘 말하는 AI를 경쟁하지만, 하룹은 일을 끝내는 AI로 갑니다
- 일을 끝내는 AI에 필요한 것은 모델이 아니라 도메인 실데이터와 검증입니다
- Opus 4.7·GPT-5.5 작업별 라우팅 위에 하룹 자체 모델들이 결과를 다듬습니다
안녕하세요, 하룹입니다. 어제(4월 23일) OpenAI가 GPT-5.5를 공개했습니다. 그리고 오늘 오전 API가 열리자마자, 하룹은 몇 시간 만에 하룹 슈퍼AI 탑재를 마쳤습니다.
지난주 Claude Opus 4.7에 이어 두 번째입니다. 새 프런티어 모델이 나오면 하루 안에 하룹에 들어오는 것 — 이 속도는 이제 하룹의 기본값이라고 생각해주셔도 됩니다. 지난 발표에서 말씀드렸듯, 하룹 슈퍼AI는 특정 모델에 종속되지 않는 구조이기 때문입니다.
GPT-5.5는 분명 더 좋아졌습니다
GPT-5.5는 인상적인 모델입니다. 더 정확하게 이해하고, 더 자연스럽게 말합니다. OpenAI 스스로 가장 똑똑하고 가장 직관적인 모델이라고 소개했고, 직접 써보면 그 말이 과장이 아니라는 것을 느낄 수 있습니다. 그리고 흥미로운 대목이 하나 있었습니다. 발표 내용에 "작업이 끝날 때까지 도구를 넘나든다"는 표현이 등장하기 시작했다는 점입니다.
일주일 전, 하룹은 발표문에서 이렇게 말씀드렸습니다. AI는 답변을 받는 도구에서, 일을 맡기는 존재로 진화한다고. 세계가 조금씩 그 방향을 말하기 시작했습니다. 우리는 이것을 우연이라고 생각하지 않습니다. 그 방향이 맞기 때문입니다.
그래도 시장의 중심은 여전히 "말"입니다
하지만 제품들을 열어보면, 경쟁의 본질은 아직 그대로입니다. 누가 더 잘 이해하고, 누가 더 잘 말하는가. GPT-5.5도 결국 그 경쟁의 가장 앞에 선 모델입니다. 인간의 명령을 이해하는 가장 뛰어난 대화상대를 만드는 경쟁 — 그것이 2026년 4월의 AI 시장입니다.
하룹이 가는 방향은 다릅니다. 하룹이 만드는 것은 더 잘 말하는 AI가 아니라, 병원의 일을 끝내는 AI입니다. 대화상대가 아니라 업무자입니다. 명령을 이해하는 데서 멈추지 않고, 병원이 준 목표를 실제로 수행해서 결과물로 돌아오는 실행 시스템입니다.

일을 끝내는 AI는 왜 어려운가요?
말을 더 잘하는 것은 모델의 문제입니다. 모델이 좋아지면 모두가 함께 좋아지고, 그래서 그 경쟁은 결국 비슷한 곳으로 수렴합니다. 그러나 일을 끝내는 것은 모델 바깥의 문제입니다. 무엇이 좋은 결과물인지 판별하는 도메인 기준, 실데이터, 검증 레이어, 그리고 결과를 책임지는 운영이 필요합니다.
병원마케팅으로 좁히면 이렇습니다. 십수 년치 진료과별 키워드 데이터, 네이버 노출 로직의 변화 이력, 의료광고법 심의 사례, 상담으로 이어지는 전환 구조 — 이것들이 없으면 AI는 그럴듯한 말을 만들 수는 있어도, 병원에 실제로 도움이 되는 일을 끝낼 수는 없습니다. 그리고 이것은 범용 모델이 아무리 좋아져도 저절로 생기지 않습니다. 하룹이 8년간 쌓아온 것이 정확히 이것입니다. AI 업계에 계신 분들이라면, 이 차이가 무엇을 의미하는지 아실 거라 생각합니다.
하룹 슈퍼AI는 지금 이렇게 일하고 있습니다
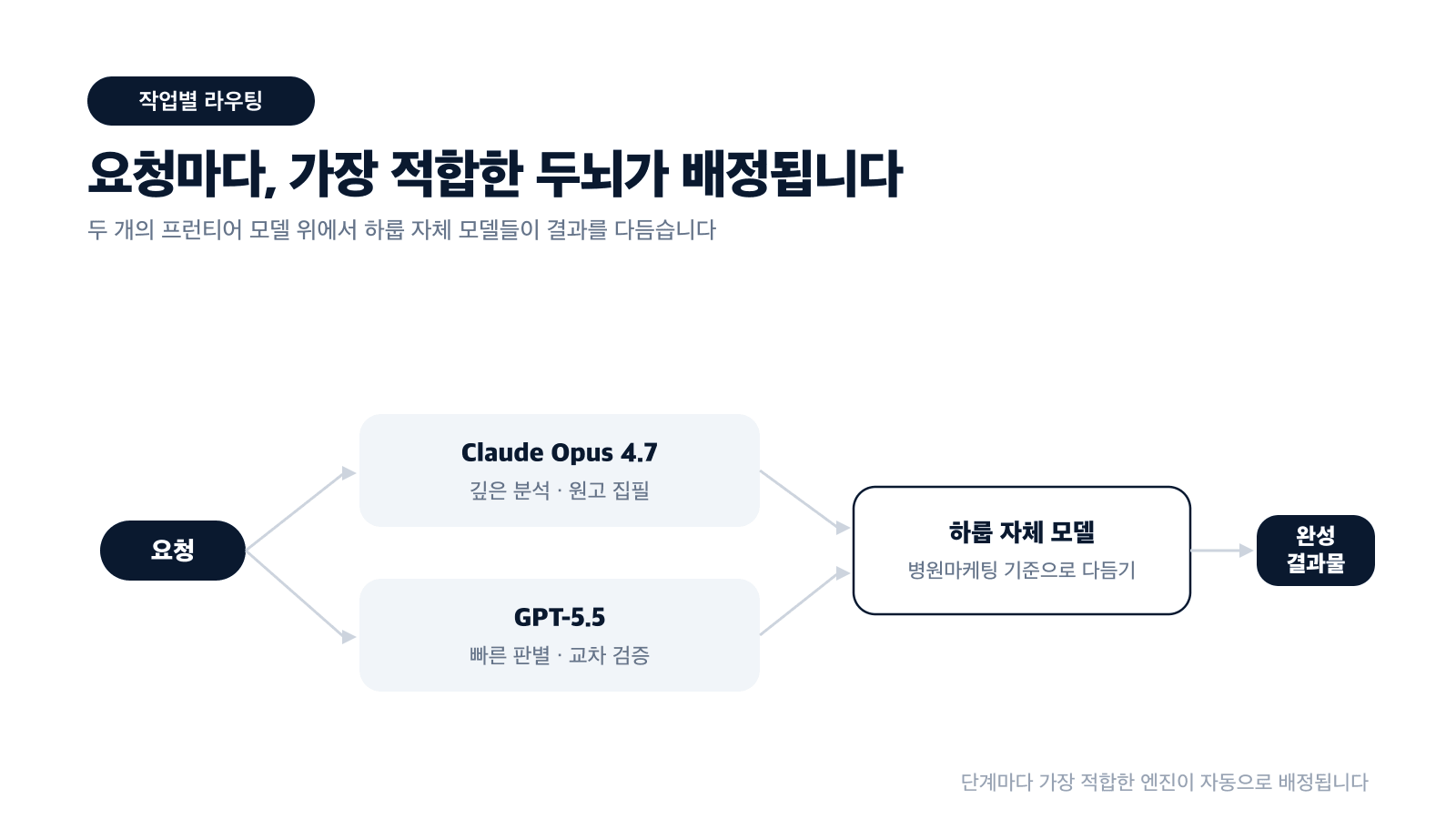
이번 탑재로 하룹 슈퍼AI는 Claude Opus 4.7과 GPT-5.5를 작업 성격에 따라 나누어 씁니다. 깊은 추론이 필요한 분석과 집필, 빠른 판별과 분류, 수집한 데이터의 교차 검증 — 단계마다 가장 적합한 두뇌가 배정되고, 그 위에서 애드파인더, 큐스타, 에이스, 하루비 같은 하룹의 자체 모델들이 병원마케팅의 기준으로 결과를 다듬습니다.
지난 발표에서 말씀드렸던 비공개 베타 준비도 순조롭습니다. 방대한 하룹 데이터의 호출 안정성을 끌어올리는 작업이 막바지에 있고, 진행 소식은 준비가 되는 대로 알려드리겠습니다.
말을 더 잘하는 AI의 경쟁은 결국 한곳으로 수렴할 것입니다. 일을 끝내는 AI의 경쟁은 이제 막 시작되었고, 하룹은 그 출발선에 가장 먼저 서 있습니다. 다음 소식도 빠르게 전하겠습니다. 감사합니다.


